Ya hicimos todos los preparativos para realizar el proceso de Failover, así que ya es tiempo de ejecutar esta actividad y visualizar los cambios a nivel de ambos Datacenter con los equipos.
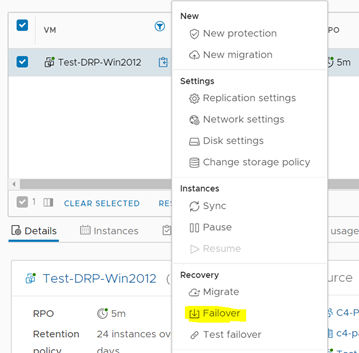
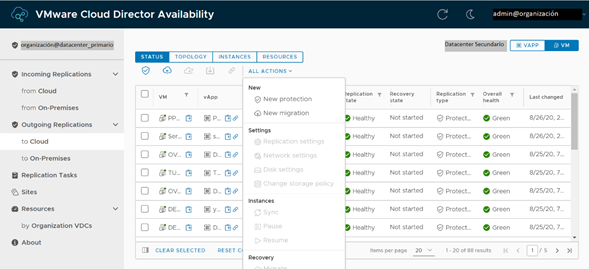
Para iniciar el proceso de failover, seleccionamos el servidor de pruebas en la consola principal de vCloud Availability y en la sección de Actions, seleccionamos Failover.
Iniciando el proceso de failover.
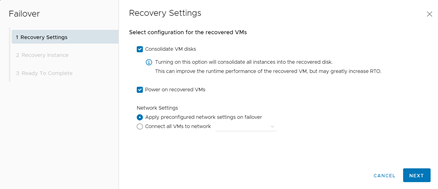
En la ventana emergente configuraremos las primeras opciones de nuestro proceso. En primer lugar, nos da la opción de realizar un consolidado de todas las instancias creadas, a fin de minimizar los problemas de integridad que puedan existir. Es una opción que, al habilitarla, incrementará el RTO del proceso (tiempo de recuperación). Posteriormente, nos entrega la opción de encender el servidor en el Datacenter de Contingencia una vez finalizado el failover y nos permite cambiar la configuración de red, conectando el servidor a otra VLAN. Esto es particularmente útil si el Datacenter de Contingencia no está extendido en Capa 2 al Datacenter Principal. Una vez seleccionadas las opciones, damos clic a Next.
Configuración inicial del failover.
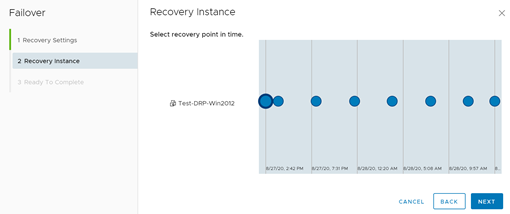
Posteriormente, debemos definir el punto de restauración. Es importante saber que mientras más antiguo sea el punto que escojamos, mayor debería ser la cantidad de datos perdidos en el proceso. Generalmente, se utilizan puntos antiguos cuando el failover se realiza por problemas de integridad de datos más que por un evento disruptivo desde el ámbito de la continuidad. Una vez seleccionado el punto de recuperación, hacemos clic en Next.
Seleccionando el punto de failover.
En la ventana de resumen, damos clic en Finish para confirmar el proceso de failover.
Resumen del proceso.
Gráficamente, podemos ver como comienza el proceso de failover.
Seguimiento en línea del proceso.
Una vez terminado el proceso de failover, podremos visualizar como nuestro servidor se ha encendido en el Datacenter de Contingencia.
Servidor creado en Datacenter de Contingencia.
Por otro lado, el servidor sigue encendido en el Datacenter Principal.
En el Datacenter Principal, nuestro servidor de pruebas se mantiene encendido.
Por otro lado, en el Datacenter de Contingencia el disco independiente que visualizamos en el artículo anterior ya está asociado al server que se encuentra prendido en dicho Datacenter.
La búsqueda en el Datacenter de Contingencia del disco independiente asociado a nuestro servidor de pruebas no da resultados.
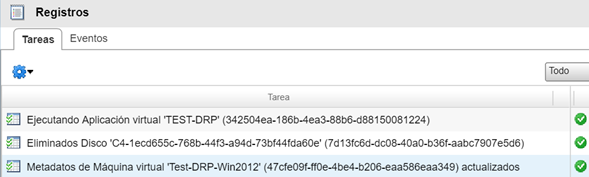
Se puede visualizar, además, en el Datacenter de Contingencia, las tareas asociadas al proceso de failover.
Tareas de creación del servidor de pruebas en el Datacenter de Contingencia. Registro de vCloud Director.
Tareas de eliminación del disco independiente, una vez que está asociado a la nueva máquina creada en el Datacenter de Contingencia.
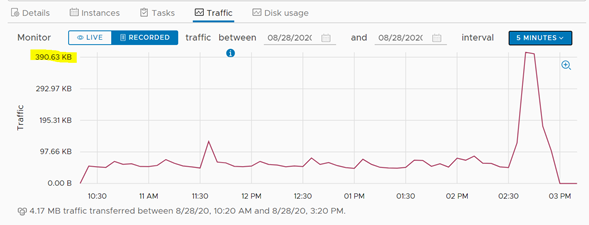
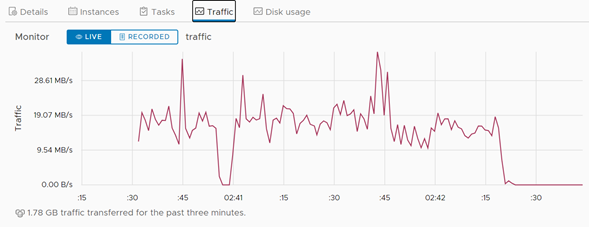
Una vez terminado el proceso de failover, que para el caso del servidor de pruebas duró algunos segundos, se puede visualizar que, a nivel de tráfico de red, la cantidad de datos que se movieron de un Datacenter a otro fue irrelevante.
Visualización de la transferencia de archivos durante el proceso de failover.
En el caso de un escenario de Disaster Recovery real, el Datacenter Principal no está habilitado. Por ende, una vez que se restituye el servicio de dicho Datacenter y para preparar la vuelta a operaciones normales, se debe realizar la protección reversa, vale decir, habilitar el servicio de réplica, pero esta vez desde el Datacenter de Contingencia hacia el Datacenter Principal. Este aspecto lo revisaremos en el próximo artículo de esta serie. ¡Nos vemos!
En el artículo anterior revisamos el proceso de prueba de failover de un servidor utilizando vCloud Availability de VMware. A continuación, entraremos en tierra derecha analizando el proceso de failover y como se reflejan las actividades dentro de esta fase. Comencemos.
La situación previa al failover
Cuando realizamos la protección de nuestros servidores utilizando la herramienta vCloud Availability, lo que hacemos es crear una unidad de disco independiente que no queda asociada a máquina virtual alguna. Esta unidad se asocia a las réplicas que se realizan de cada servidor protegido; así podremos corroborar que, si no hemos aplicado failover a ningún servidor del Datacenter Principal, el Datacenter de Contingencia no tendrá máquinas encendidas, pero sí tendrá unidades de disco creadas según cuantas máquinas estemos protegiendo.
En el Datacenter Principal, tenemos 99 máquinas, de las cuales 89 están protegidas.
En el Datacenter de Contingencia, no hay servidores encendidos.
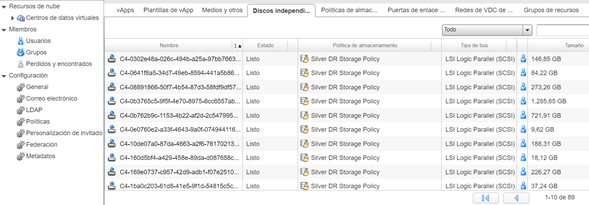
Sin embargo, en el Datacenter de Contingencia hay 89 discos independientes creados, los cuales están asociados a los 89 servidores protegidos.
Cuando creamos la protección hacia nuestro servidor de pruebas, vCloud Availability identifica la unidad de disco independiente que creó en el Datacenter de Contingencia. Esto podemos revisarlo haciendo clic en la sección Replication Tasks de la consola de administración de la herramienta.
Identificando el ID de Disco asociado al servidor de pruebas.
Esto lo podemos corroborar en el Datacenter de Contingencia, buscando los discos independientes por su ID.
Encontramos el disco independiente asociado a nuestro servidor de pruebas en el Datacenter de Contingencia.
Preparando el proceso de failover
Escribí este artículo al día siguiente de que establecí la protección del servidor de pruebas usando vCloud Availability. Esto lo hice para poder generar varios puntos de restauración y réplica durante la noche y así poder verificar que este trabajo se hizo adecuadamente para así realizar el failover más tarde.
Una vez ingresando en la consola principal de vCloud Availability, vamos a ir a la sección Outgoing Replications – To Cloud para buscar nuestro servidor y verificar el status del servicio de réplica.
Verificando el estado del servicio de réplicas para nuestro servidor de pruebas.
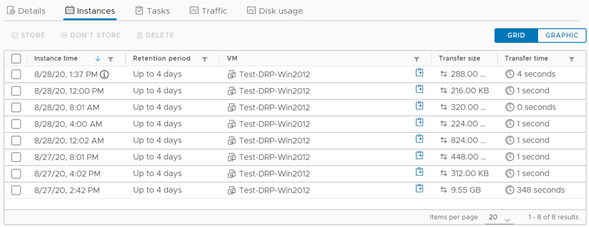
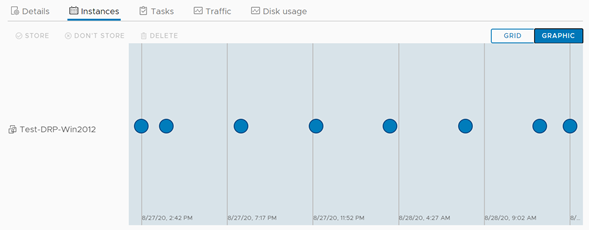
En el panel de control podremos corroborar rápidamente si nuestro servidor se encuentra en buen estado en cuanto a su servicio de réplicas, encontrando además información útil sobre el RPO, su última sincronización y el perfil de SLA que posee el mismo. Más abajo, podemos pinchar en Instances para visualizar el estado de la generación de instancias, en base a la política que definimos para el servidor al momento de crear la protección. Esta vista la podemos tener en formato lista o gráfico.
Vista de réplicas – Lista.
Vista de réplicas – Gráfica.
Como dato interesante, debido a la configuración del RPO, siempre se debe generar una réplica en un intervalo inferior al definido como RPO, lo cual pude corroborar dado que mientras sacaba las capturas de pantalla el sistema volvió a replicar.
Nueva réplica, 5 minutos después.
La visión de réplicas nos muestra gráficamente que cada 5 minutos aparece una nueva réplica, no persistente, que reemplaza la anterior, y adicionalmente a esto, cada 4 horas se genera una réplica persistente (o instancia), acorde a la configuración que aplicamos para la protección. Es momento entonces de ejecutar el proceso de failover. Y esto lo veremos en el siguiente artículo de esta serie. ¡No se lo pierdan!
En el artículo anterior revisamos el proceso de protección de un servidor utilizando vCloud Availability de VMware. A continuación, nos adentraremos en la siguiente fase del ciclo: el failover. Y para ello, utilizaremos una funcionalidad que posee vCloud Availability que se llama Test Failover. Comencemos.
Probando el failover sin afectar el servicio
En un proceso normal de failover, a partir del disco “oculto” en el Datacenter de Contingencia se crea un servidor de iguales características al original (manteniendo la configuración de disco, CPU, memoria y red), para posteriormente encenderlo y culminar el proceso.
Sin embargo, una estrategia atractiva utilizada para propósitos de troubleshooting o para realizar la primera prueba de un DRP es utilizar la opción de Test Failover de vCloud Availability. Esta opción permite levantar una copia de la máquina de origen en el Datacenter de Contingencia sin apagar el servidor original. Esto permite, por ejemplo, probar distintas instancias a fin de detectar cual de ellas no alcanzó a ser afectada por un malware y restablecer de manera definitiva el servidor afectado a partir de dicha instancia.
Por otro lado, la opción de Test Failover puede ayudar a realizar pruebas funcionales, aunque por lo general este proceso tiene limitantes a nivel de red. Esto porque al ser una copia del equipo replicado, conectar dicha máquina directamente a la red podría causar más de un conflicto.
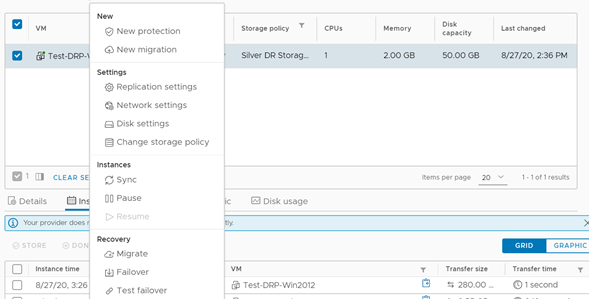
Para realizar un test failover, debemos ubicar nuestro servidor en la consola principal de vCloud Availability y seleccionar la opción Test Failover.
Iniciando un proceso de Test Failover.
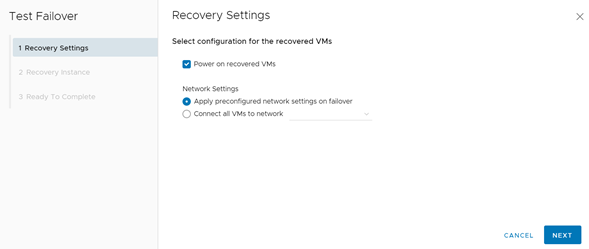
El asistente de este proceso es muy sencillo. En la primera opción podemos seleccionar si queremos o no encender la VM o si la queremos configurar a alguna red en particular. Una vez seleccionadas las opciones, damos clic en Next.
Configurando el test failover.
Posteriormente, debemos seleccionar la instancia de recuperación. Aquí aparecen dos opciones; la primera de ellas apunta a usar la última réplica existente (que debe estar dentro del rango de RPO configurado), o bien, utilizar una instancia anterior. Esto dependerá de la configuración de instancias que hayamos seleccionado cuando creamos la réplica para este servidor. El asistente, al seleccionar la segunda opción, muestra gráficamente las réplicas existentes, por lo que podemos seleccionar la que queramos utilizar.
Seleccionando la instancia para hacer el test.
Resumen del proceso.
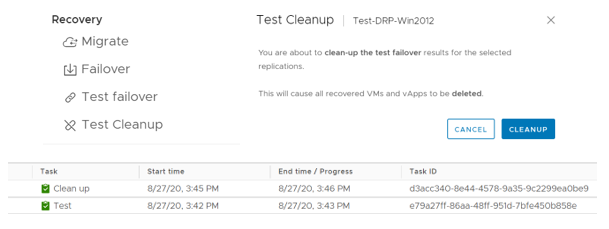
El proceso de prueba del failover es por lo general bastante rápido y efectivo. Una vez completado, tendremos a nuestro servidor original en el Datacenter Principal funcionando de manera normal y una copia de dicho servidor en el Datacenter de Contingencia, el cual podremos abrir y revisar cuando estimemos conveniente. Una vez terminadas las pruebas, debemos seleccionar la opción Test Cleanup para borrar la máquina con la cual hicimos la prueba.
Realizando el cleanup para culminar el proceso.
Y esto es todo por hoy. En el siguiente artículo, haremos un failover, para medir tiempos, y estableceremos la protección reversa para asegurar la réplica desde el Datacenter de Contingencia hacia el Datacenter Principal. ¡Nos vemos!
En el artículo anterior describimos el proceso general de Disaster Recovery utilizando vCloud Availability de VMware. A continuación, nos adentraremos en las distintas fases del ciclo, para lo cual hemos montado en nuestro ambiente una máquina de pruebas con las siguientes especificaciones:
Especificación
Valor
Sistema Operativo
Windows Server 2012 R2 x64
Memoria RAM
2GB
CPU
1vCPU
Disco
50GB en una unidad
Especificaciones del servidor de pruebas.
Fase 1: Protección
En la primera fase del proceso, se debe habilitar el servicio de réplicas hacia el Datacenter de Contingencia. En esta etapa se definirán ciertos parámetros clave para el proceso, los cuales revisaremos en el paso a paso.
En la primera fase del proceso, se debe habilitar el servicio de réplicas hacia el Datacenter de Contingencia. En esta etapa se definirán ciertos parámetros clave para el proceso, los cuales revisaremos en el paso a paso.
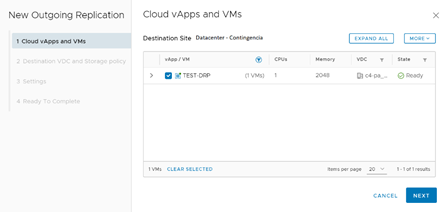
Una vez que ya iniciamos sesión en la herramienta (que está previamente instalada tanto en el Datacenter Principal como en el de Contingencia, debemos ingresar a la sección Outgoing Replications. En esta sección aparecerán todos aquellos servidores para los cuales el servicio de réplica esté habilitado, tanto hacia otro Datacenter en la nube como hacia plataformas On-Premise. En este caso, utilizaremos la sección To Cloud y pincharemos All Actions, para luego dar clic en New Protection.
Configurando la protección en vCloud Availability.
Después de iniciar sesión con las credenciales de vCloud Availability en el Datacenter de Contingencia, en la ventana emergente, localizamos el servidor al cual habilitaremos la réplica, para luego hacer clic en Next.
Definiendo el servidor a replicar.
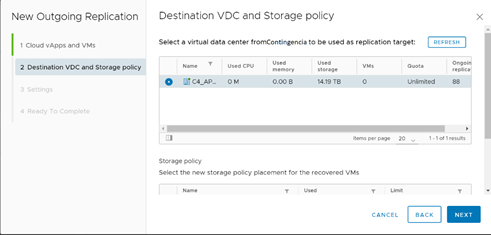
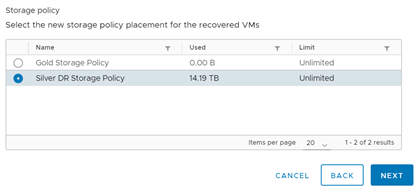
En la siguiente ventana, se deben configurar las políticas de storage y la organización de destino en donde se instalará el servicio de réplica. Una vez configurado esto, daremos clic en Next para pasar a la configuración medular de la réplica.
Definiendo Datacenter de Destino.
Definiendo política de storage.
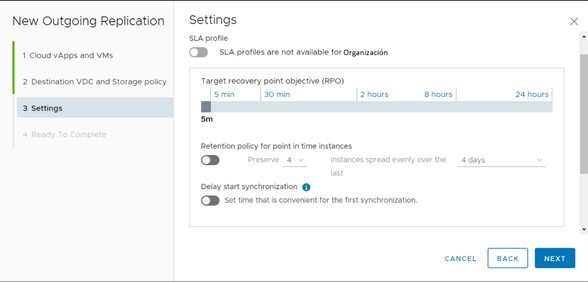
El primer punto que configurar tiene relación con el RPO. El RPO o Recovery Point Objetive guarda relación con la cantidad de data que estamos dispuestos a perder en caso de existir un escenario de desastre. Esto cobra especial relevancia en los servidores transaccionales, que deberían apuntar a un RPO bastante pequeño a fin de que, en caso de una pérdida de servicio que obligue a un proceso de failover, disminuya la cantidad de transacciones perdidas o corruptas. En los servicios no transaccionales, se puede configurar un RPO mayor ya que no se espera que estos servidores sufran grandes cambios a nivel estructural en el tiempo.
Configuración de la protección.
RPO.
Ahora bien, la definición de RPO impacta directamente en la frecuencia de réplicas que tiene el servicio. Herramientas como vCloud Availability realizar réplicas similares a un backup incremental y su frecuencia dependerá directamente de la configuración del parámetro de RPO. Esto quiere decir que si configuro un RPO de 5 minutos, el sistema tiene como máximo 5 minutos entre réplicas, a fin de garantizar que en caso de que se tenga que aplicar un failover, la data recreada en el Datacenter de Contingencia tenga a lo sumo 5 minutos de antigüedad. Esta herramienta permite parametrizar el RPO en un rango que varía desde los 5 minutos hasta las 24 horas.
Otro punto relevante en la configuración del servicio de réplicas guarda relación con las instancias.
Configurando instancias.
El servicio de réplica, al realizarse de manera tan continua (podrían realizarse como máximo 288 réplicas diarias) podría impactar fuertemente en el uso de disco. Para evitar esto, el servicio está diseñado para mantener solamente la réplica más reciente como disponible, vale decir, cada réplica va “pisando” la anterior. Esta característica de diseño implica un riesgo inherente al servicio: si la máquina de origen por algún motivo queda corrupta (malware, borrado accidental de datos, etc.), en cosa de minutos será replicada al Datacenter de Contingencia en las mismas condiciones. Por este motivo, si el failover está motivado, por citar un ejemplo, en un evento de ramsonware, no solucionará el problema, sino que lo replicará al Datacenter de Contingencia. En estos casos y como una alternativa al uso de respaldos, es que el servicio de réplicas usa el concepto de instancias.
Las instancias son réplicas persistentes, y vCloud Availability permite almacenar hasta 24 instancias para tener puntos de restauración adicionales que permitan volver a un momento anterior al de la última réplica realizada. Esto permitiría recuperar equipos que han sido afectados a nivel de integridad de datos a un estado previo al evento. Además de configurar el número de instancias (desde 1 a 24) se puede configurar el tiempo en el cual se quieren distribuir estos puntos, lo que varía desde 1 día hasta 1 año. Así, si se configura una política de 24 instancias en 1 día, esto quiere decir que se generarán puntos de réplica persistentes cada 60 minutos.
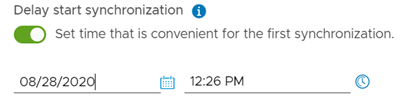
Considerando que el proceso de protección generará una réplica inicial del total del disco del servidor a proteger, se ha añadido la alternativa de programar esta réplica inicial a una fecha y hora posterior, a fin de minimizar el impacto a nivel de redes que pueda ocasionar este proceso.
Configuración de primera réplica.
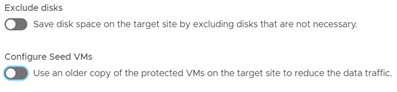
Finalmente, se puede configurar una exclusión de discos no necesarios para optimizar el proceso o usar una copia antigua de otras máquinas ya protegidas para reducir el tráfico de red. A esto último se le llama Seed VMs o Máquinas semilla.
Configuraciones adicionales.
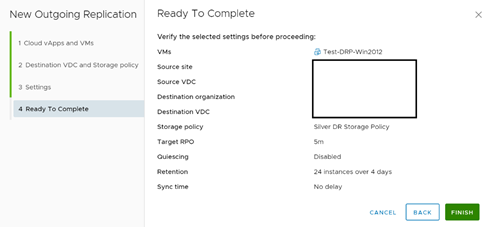
Una vez que damos clic en Next, muestra un cuadro resumen de la configuración y podemos dar clic en Finish para terminar el proceso de protección.
Resumen de configuración.
Una vez que se inicia el proceso de configuración, vCloud Availability crea un objeto de disco en el Datacenter de Contingencia, el cual queda oculto y no queda asociado a ninguna máquina. Posterior a eso, se establece el proceso de réplica inicial, en el cual se envía en formato comprimido el disco utilizado al Datacenter de Contingencia. Para propósitos de esta prueba, el sistema se demoró cerca de 8 minutos en sincronizar aproximadamente 9,5 GB iniciales de Datos.
Estadísticas de flujo de datos en tiempo real durante la primera réplica.
Datos sobre las réplicas creadas.
Y ¡esto ha sido todo por hoy! El próximo artículo será para ahondar en el proceso de failover, pasando primero por la prueba de este. Nos vemos en otra ocasión.
Una de las estrategias de Disaster Recovery más utilizadas en los entornos de Datacenter virtualizados es el uso de herramientas de réplica de máquinas virtuales entre un Datacenter Principal y un Datacenter Secundario (o de Contingencia). Estas herramientas están continuamente replicando en segundo plano los cambios a nivel de configuración y contenido de los servidores hacia el segundo Datacenter, manteniendo los servidores en dicho Datacenter apagados hasta el momento en que sea necesario aplicar un proceso de Failover. En este sentido, las herramientas de réplica constituyen una estrategia de contingencia que, si bien es manual, es muy eficiente, dado que el proceso de Failover de un servidor puede resolverse en cosa de minutos.
En los siguientes artículos, revisaremos como funciona el proceso de Disaster Recovery usando una herramienta de réplica nativa de VMware: vCloud Availability.
Según indica VMware en su descripción de producto (https://www.vmware.com/cl/products/cloud-director-availability.html), vCloud Availability es una herramienta de tipo DRaaS (Disaster Recovery as a Service), la cual se ha diseñado para ofrecer diversos servicios de incorporación, migración y recuperación ante desastres a través de un proceso sencillo, seguro y rentable, entre Datacenters Virtuales (VDC). Esta solución forma parte de la plataforma de proveedor de nube de VMware (VMware Cloud Provider Platform) y como tal se integra de forma nativa con VMware Cloud Director. Por otra parte y en cuanto a seguridad, que es un aspecto siempre relevante en este tipo de soluciones, los datos en reposo y en circulación asociados al servicio de réplica se encuentran cifrados, además de ofrecer compresión integrada del tráfico de replicación y cifrado TLS integral.
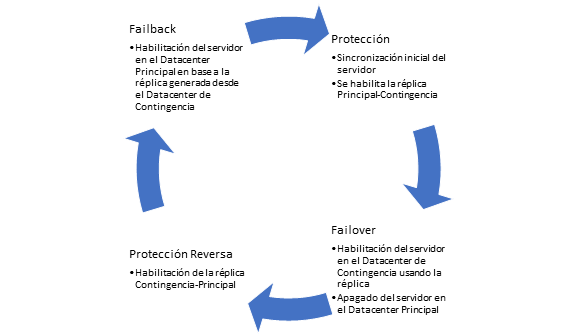
El proceso de Disaster Recovery utilizando vCloud Availability consiste en una serie de fases, que se describen en el siguiente diagrama y que serán analizados en los siguientes artículos:
Fases de un proceso de Disaster Recovery usando vCloud Availability.
Protección. Corresponde a la fase inicial del proceso, en donde se establece la primera réplica del servidor desde el Datacenter Principal al Datacenter de Contingencia y se configura el servicio de réplica continua.
Failover. Corresponde a la primera actividad propia de un proceso de Disaster Recovery. En esta fase, se activa el Servidor en el Datacenter de Contingencia usando una réplica disponible desde el Datacenter Principal. En caso de que el servidor en el Datacenter Principal aún estuviese encendido, en esta fase dicho servidor es apagado.
Protección Reversa: Una vez que el servidor ya se encuentra operativo en el Datacenter de Contingencia, se debe habilitar el servicio de réplica en el sentido inverso, vale decir desde el Datacenter de Contingencia hacia el Datacenter Principal.
Failback (Failover inverso). De manera similar al proceso de Failover, en esta fase de vuelta a operaciones normales se utiliza una réplica disponible desde el Datacenter de Contingencia para volver a habilitar el servidor en el Datacenter Principal.
Reprotección: Una vez vuelto el servidor a operaciones normales, se habilita nuevamente el servicio de réplica hacia el Datacenter de Contingencia, cerrando el ciclo.
En el próximo artículo, revisaremos la primera fase de este proceso: La protección de los servidores.