En el artículo anterior revisamos el proceso de prueba de failover de un servidor utilizando vCloud Availability de VMware. A continuación, entraremos en tierra derecha analizando el proceso de failover y como se reflejan las actividades dentro de esta fase. Comencemos.
La situación previa al failover
Cuando realizamos la protección de nuestros servidores utilizando la herramienta vCloud Availability, lo que hacemos es crear una unidad de disco independiente que no queda asociada a máquina virtual alguna. Esta unidad se asocia a las réplicas que se realizan de cada servidor protegido; así podremos corroborar que, si no hemos aplicado failover a ningún servidor del Datacenter Principal, el Datacenter de Contingencia no tendrá máquinas encendidas, pero sí tendrá unidades de disco creadas según cuantas máquinas estemos protegiendo.

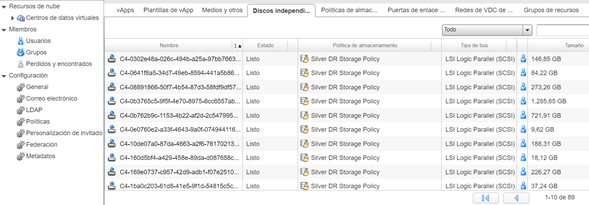
Cuando creamos la protección hacia nuestro servidor de pruebas, vCloud Availability identifica la unidad de disco independiente que creó en el Datacenter de Contingencia. Esto podemos revisarlo haciendo clic en la sección Replication Tasks de la consola de administración de la herramienta.

Esto lo podemos corroborar en el Datacenter de Contingencia, buscando los discos independientes por su ID.

Preparando el proceso de failover
Escribí este artículo al día siguiente de que establecí la protección del servidor de pruebas usando vCloud Availability. Esto lo hice para poder generar varios puntos de restauración y réplica durante la noche y así poder verificar que este trabajo se hizo adecuadamente para así realizar el failover más tarde.
Una vez ingresando en la consola principal de vCloud Availability, vamos a ir a la sección Outgoing Replications – To Cloud para buscar nuestro servidor y verificar el status del servicio de réplica.

En el panel de control podremos corroborar rápidamente si nuestro servidor se encuentra en buen estado en cuanto a su servicio de réplicas, encontrando además información útil sobre el RPO, su última sincronización y el perfil de SLA que posee el mismo. Más abajo, podemos pinchar en Instances para visualizar el estado de la generación de instancias, en base a la política que definimos para el servidor al momento de crear la protección. Esta vista la podemos tener en formato lista o gráfico.
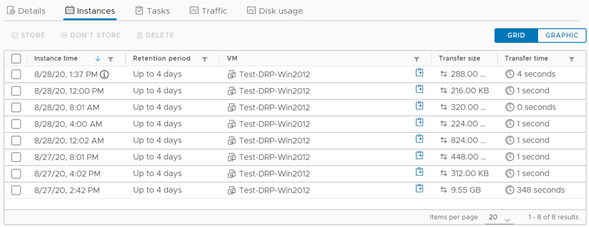
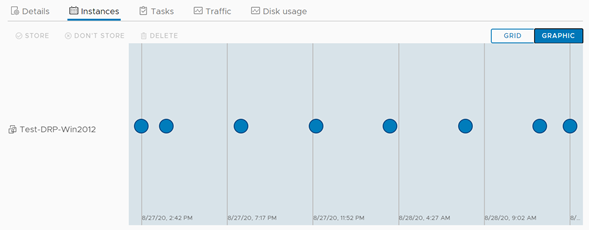
Como dato interesante, debido a la configuración del RPO, siempre se debe generar una réplica en un intervalo inferior al definido como RPO, lo cual pude corroborar dado que mientras sacaba las capturas de pantalla el sistema volvió a replicar.

La visión de réplicas nos muestra gráficamente que cada 5 minutos aparece una nueva réplica, no persistente, que reemplaza la anterior, y adicionalmente a esto, cada 4 horas se genera una réplica persistente (o instancia), acorde a la configuración que aplicamos para la protección. Es momento entonces de ejecutar el proceso de failover. Y esto lo veremos en el siguiente artículo de esta serie. ¡No se lo pierdan!

[…] « Usando vCloud Availability para escenarios de Disaster Recovery (Parte 4) […]