Ya hicimos todos los preparativos para realizar el proceso de Failover, así que ya es tiempo de ejecutar esta actividad y visualizar los cambios a nivel de ambos Datacenter con los equipos.
Para iniciar el proceso de failover, seleccionamos el servidor de pruebas en la consola principal de vCloud Availability y en la sección de Actions, seleccionamos Failover.
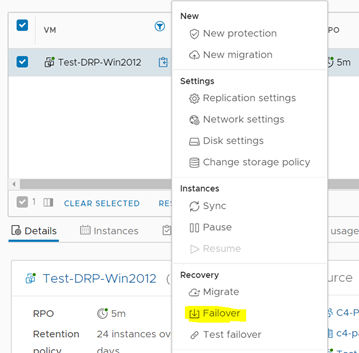
En la ventana emergente configuraremos las primeras opciones de nuestro proceso. En primer lugar, nos da la opción de realizar un consolidado de todas las instancias creadas, a fin de minimizar los problemas de integridad que puedan existir. Es una opción que, al habilitarla, incrementará el RTO del proceso (tiempo de recuperación). Posteriormente, nos entrega la opción de encender el servidor en el Datacenter de Contingencia una vez finalizado el failover y nos permite cambiar la configuración de red, conectando el servidor a otra VLAN. Esto es particularmente útil si el Datacenter de Contingencia no está extendido en Capa 2 al Datacenter Principal. Una vez seleccionadas las opciones, damos clic a Next.
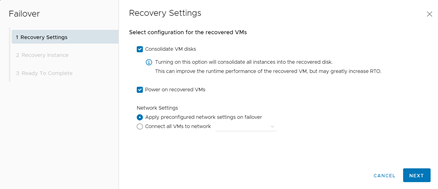
Posteriormente, debemos definir el punto de restauración. Es importante saber que mientras más antiguo sea el punto que escojamos, mayor debería ser la cantidad de datos perdidos en el proceso. Generalmente, se utilizan puntos antiguos cuando el failover se realiza por problemas de integridad de datos más que por un evento disruptivo desde el ámbito de la continuidad. Una vez seleccionado el punto de recuperación, hacemos clic en Next.
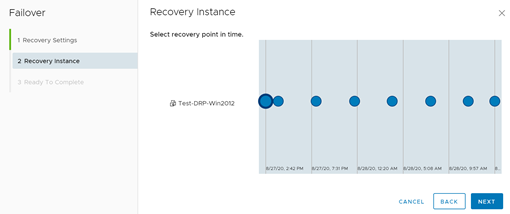
En la ventana de resumen, damos clic en Finish para confirmar el proceso de failover.

Gráficamente, podemos ver como comienza el proceso de failover.

Una vez terminado el proceso de failover, podremos visualizar como nuestro servidor se ha encendido en el Datacenter de Contingencia.

Por otro lado, el servidor sigue encendido en el Datacenter Principal.

Por otro lado, en el Datacenter de Contingencia el disco independiente que visualizamos en el artículo anterior ya está asociado al server que se encuentra prendido en dicho Datacenter.

Se puede visualizar, además, en el Datacenter de Contingencia, las tareas asociadas al proceso de failover.

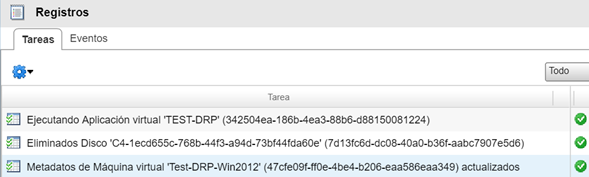
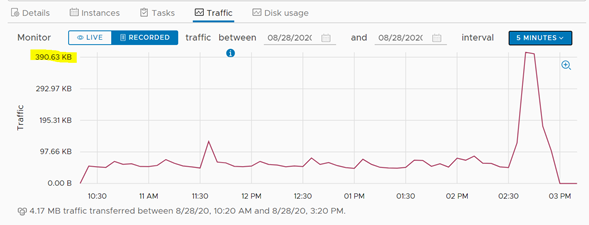
Una vez terminado el proceso de failover, que para el caso del servidor de pruebas duró algunos segundos, se puede visualizar que, a nivel de tráfico de red, la cantidad de datos que se movieron de un Datacenter a otro fue irrelevante.
En el caso de un escenario de Disaster Recovery real, el Datacenter Principal no está habilitado. Por ende, una vez que se restituye el servicio de dicho Datacenter y para preparar la vuelta a operaciones normales, se debe realizar la protección reversa, vale decir, habilitar el servicio de réplica, pero esta vez desde el Datacenter de Contingencia hacia el Datacenter Principal. Este aspecto lo revisaremos en el próximo artículo de esta serie. ¡Nos vemos!

Deja un comentario