En el artículo anterior describimos el proceso general de Disaster Recovery utilizando vCloud Availability de VMware. A continuación, nos adentraremos en las distintas fases del ciclo, para lo cual hemos montado en nuestro ambiente una máquina de pruebas con las siguientes especificaciones:
| Especificación | Valor |
| Sistema Operativo | Windows Server 2012 R2 x64 |
| Memoria RAM | 2GB |
| CPU | 1vCPU |
| Disco | 50GB en una unidad |
Fase 1: Protección
En la primera fase del proceso, se debe habilitar el servicio de réplicas hacia el Datacenter de Contingencia. En esta etapa se definirán ciertos parámetros clave para el proceso, los cuales revisaremos en el paso a paso.
En la primera fase del proceso, se debe habilitar el servicio de réplicas hacia el Datacenter de Contingencia. En esta etapa se definirán ciertos parámetros clave para el proceso, los cuales revisaremos en el paso a paso.
Una vez que ya iniciamos sesión en la herramienta (que está previamente instalada tanto en el Datacenter Principal como en el de Contingencia, debemos ingresar a la sección Outgoing Replications. En esta sección aparecerán todos aquellos servidores para los cuales el servicio de réplica esté habilitado, tanto hacia otro Datacenter en la nube como hacia plataformas On-Premise. En este caso, utilizaremos la sección To Cloud y pincharemos All Actions, para luego dar clic en New Protection.
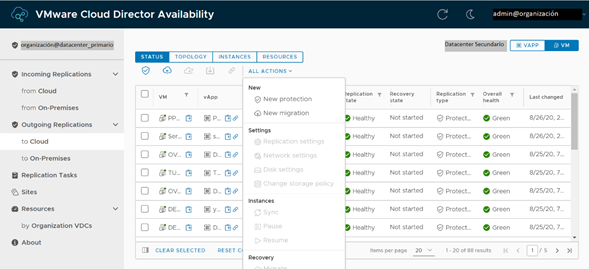
Después de iniciar sesión con las credenciales de vCloud Availability en el Datacenter de Contingencia, en la ventana emergente, localizamos el servidor al cual habilitaremos la réplica, para luego hacer clic en Next.
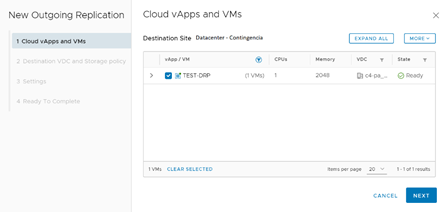
En la siguiente ventana, se deben configurar las políticas de storage y la organización de destino en donde se instalará el servicio de réplica. Una vez configurado esto, daremos clic en Next para pasar a la configuración medular de la réplica.
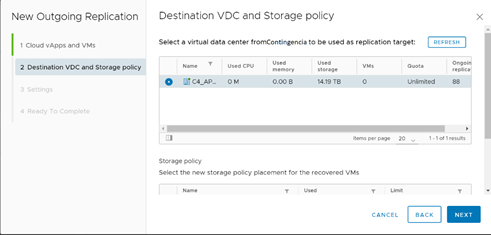
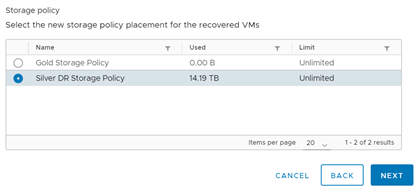
El primer punto que configurar tiene relación con el RPO. El RPO o Recovery Point Objetive guarda relación con la cantidad de data que estamos dispuestos a perder en caso de existir un escenario de desastre. Esto cobra especial relevancia en los servidores transaccionales, que deberían apuntar a un RPO bastante pequeño a fin de que, en caso de una pérdida de servicio que obligue a un proceso de failover, disminuya la cantidad de transacciones perdidas o corruptas. En los servicios no transaccionales, se puede configurar un RPO mayor ya que no se espera que estos servidores sufran grandes cambios a nivel estructural en el tiempo.
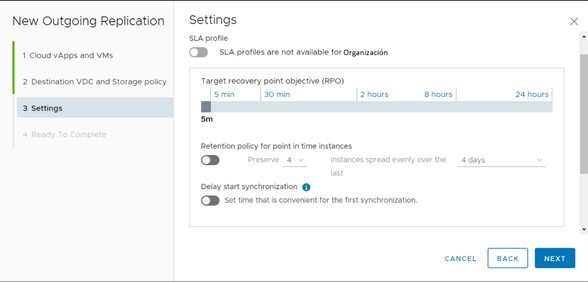

Ahora bien, la definición de RPO impacta directamente en la frecuencia de réplicas que tiene el servicio. Herramientas como vCloud Availability realizar réplicas similares a un backup incremental y su frecuencia dependerá directamente de la configuración del parámetro de RPO. Esto quiere decir que si configuro un RPO de 5 minutos, el sistema tiene como máximo 5 minutos entre réplicas, a fin de garantizar que en caso de que se tenga que aplicar un failover, la data recreada en el Datacenter de Contingencia tenga a lo sumo 5 minutos de antigüedad. Esta herramienta permite parametrizar el RPO en un rango que varía desde los 5 minutos hasta las 24 horas.
Otro punto relevante en la configuración del servicio de réplicas guarda relación con las instancias.

El servicio de réplica, al realizarse de manera tan continua (podrían realizarse como máximo 288 réplicas diarias) podría impactar fuertemente en el uso de disco. Para evitar esto, el servicio está diseñado para mantener solamente la réplica más reciente como disponible, vale decir, cada réplica va “pisando” la anterior. Esta característica de diseño implica un riesgo inherente al servicio: si la máquina de origen por algún motivo queda corrupta (malware, borrado accidental de datos, etc.), en cosa de minutos será replicada al Datacenter de Contingencia en las mismas condiciones. Por este motivo, si el failover está motivado, por citar un ejemplo, en un evento de ramsonware, no solucionará el problema, sino que lo replicará al Datacenter de Contingencia. En estos casos y como una alternativa al uso de respaldos, es que el servicio de réplicas usa el concepto de instancias.
Las instancias son réplicas persistentes, y vCloud Availability permite almacenar hasta 24 instancias para tener puntos de restauración adicionales que permitan volver a un momento anterior al de la última réplica realizada. Esto permitiría recuperar equipos que han sido afectados a nivel de integridad de datos a un estado previo al evento. Además de configurar el número de instancias (desde 1 a 24) se puede configurar el tiempo en el cual se quieren distribuir estos puntos, lo que varía desde 1 día hasta 1 año. Así, si se configura una política de 24 instancias en 1 día, esto quiere decir que se generarán puntos de réplica persistentes cada 60 minutos.
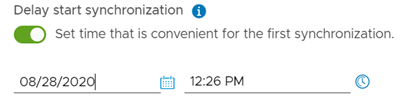
Considerando que el proceso de protección generará una réplica inicial del total del disco del servidor a proteger, se ha añadido la alternativa de programar esta réplica inicial a una fecha y hora posterior, a fin de minimizar el impacto a nivel de redes que pueda ocasionar este proceso.
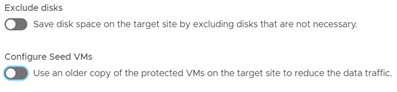
Finalmente, se puede configurar una exclusión de discos no necesarios para optimizar el proceso o usar una copia antigua de otras máquinas ya protegidas para reducir el tráfico de red. A esto último se le llama Seed VMs o Máquinas semilla.
Una vez que damos clic en Next, muestra un cuadro resumen de la configuración y podemos dar clic en Finish para terminar el proceso de protección.
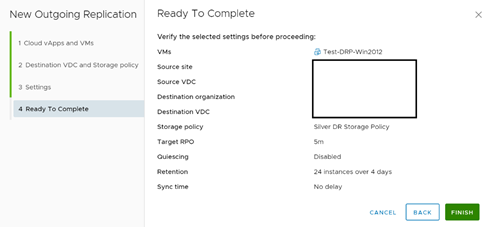
Una vez que se inicia el proceso de configuración, vCloud Availability crea un objeto de disco en el Datacenter de Contingencia, el cual queda oculto y no queda asociado a ninguna máquina. Posterior a eso, se establece el proceso de réplica inicial, en el cual se envía en formato comprimido el disco utilizado al Datacenter de Contingencia. Para propósitos de esta prueba, el sistema se demoró cerca de 8 minutos en sincronizar aproximadamente 9,5 GB iniciales de Datos.

Y ¡esto ha sido todo por hoy! El próximo artículo será para ahondar en el proceso de failover, pasando primero por la prueba de este. Nos vemos en otra ocasión.

Deja un comentario