En el capítulo anterior de esta serie, dejamos preparado el escenario de vuelta atrás, al realizar una protección reversa de nuestro servidor ya ubicado en el Datacenter de Contingencia. Esto nos permite habilitar el servicio de réplica desde dicho Datacenter al Datacenter Principal, para que una vez que nos den luz verde, poder iniciar el proceso de failback o failover reverso.
Antes de eso había olvidado comentarles algo relevante. La consola de vCloud Availability existe en ambos Datacenter, y podemos operar de manera cruzada desde cualquiera de las dos consolas. Para propósitos de este artículo, toda la operación la hemos realizado desde la consola del Datacenter Principal.
Partiremos nuestro failback revisando el estado de las réplicas de nuestro servidor de pruebas. Para ello, iremos a la consola de vCloud Availability de nuestro Datacenter Principal y en la sección Incoming Replications pincharemos en nuestro servidor, para ir a la pestaña Instances. Si hacemos esta misma acción en la consola de nuestro Datacenter de Contingencia, la única diferencia es que esta tarea deberemos hacerla en la sección Outgoing Replications.
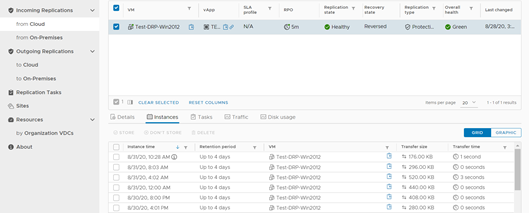
Podemos visualizar rápidamente que todo se encuentra OK. Es importante acá considerar que como este es un servidor de pruebas no transaccional, las réplicas son muy pequeñas, ya que el servidor no ha tenido transaccionalidad alguna en estos días.
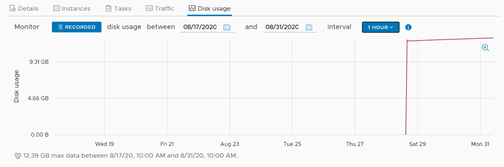
Sin embargo, podemos visualizar que el server ha generado un disco activo de unos 12 GB, los cuales se replicaron inicialmente a gran velocidad gracias a los algoritmos de compresión de la herramienta.
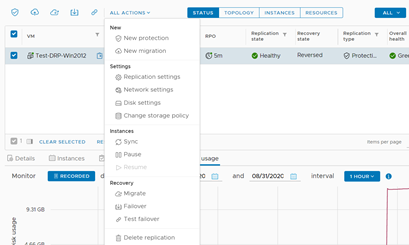
Llegó entonces el momento de realizar el failback. Para ello, en la consola de vCloud Availability, seleccionamos nuestro servidor y en Actions seleccionamos Failover.
De manera similar a lo que vimos un par de artículos atrás, configuraremos las opciones de nuestro proceso.

Posteriormente a esto, se debe seleccionar el punto de recuperación utilizado para el failback. Como este artículo lo escribí después de realizar el anterior, existen más puntos de recuperación creados.
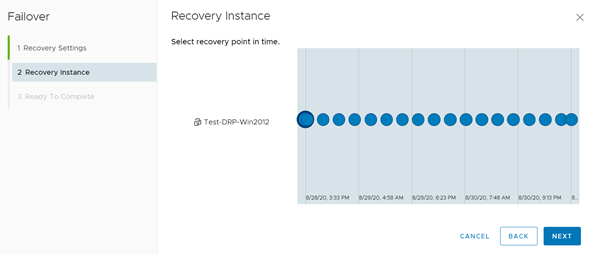
Finalmente, en el cuadro de resumen de la operación se destaca que el proceso se realizará hacia el Datacenter Principal. Una vez que demos clic en Finish comenzará el proceso.

Gráficamente, podemos ver como comienza el proceso de failback.

Una vez terminado el proceso de failback, podremos visualizar como nuestro servidor se ha encendido en el Datacenter Principal. Es importante recalcar que, en esta ocasión, se crea una nueva vApp, sin eliminar la anterior.
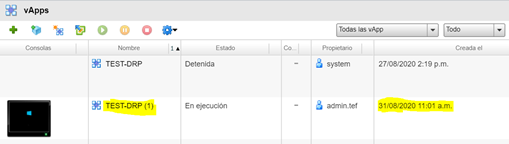
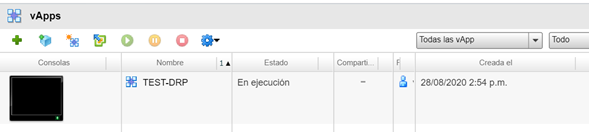
Por otro lado, el servidor sigue encendido en el Datacenter de Contingencia.
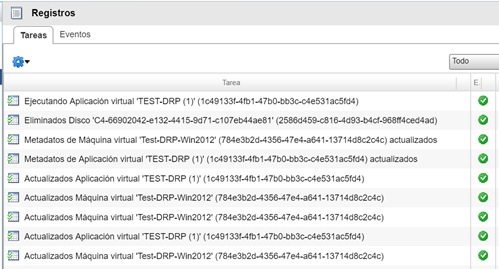
Se puede visualizar, además, en el Datacenter Principal, las tareas asociadas al proceso de failback.
Una vez terminado el proceso de failover, que para el caso del servidor de pruebas duró algunos segundos, se puede visualizar que, a nivel de tráfico de red, la cantidad de datos que se movieron de un Datacenter a otro fue irrelevante.
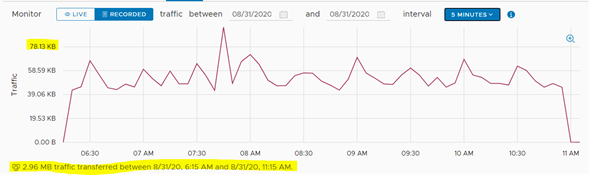
Para cerrar el ciclo del DRP, debemos realizar la re-protección del servidor. Con esta tarea, se reestablecerá el servicio de réplica desde el Datacenter Principal hacia el Datacenter de Contingencia, lo cual eliminará el servidor desde el segundo Datacenter.
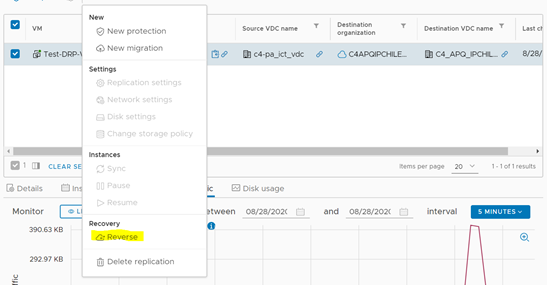
Para ello, iremos a nuestro servidor de pruebas y seleccionaremos Reprotect dentro del listado de acciones.
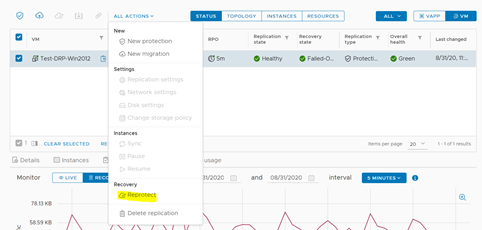
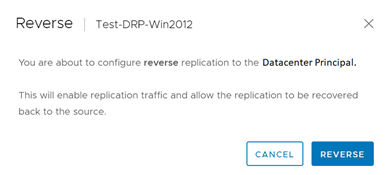
En la ventana emergente, daremos clic a Reverse para iniciar el proceso de re-protección.
Podemos seguir el status del proceso de re-protección en la consola principal.

Al igual como pasó anteriormente, al cabo de unos segundos el servidor desaparecerá de la sección Incoming Replications, para volver a la sección Outgoing Replications como estaba originalmente.
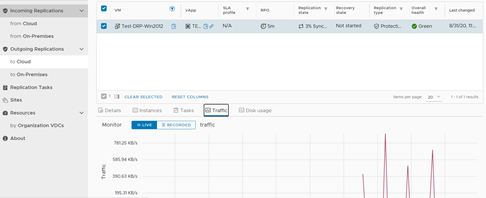
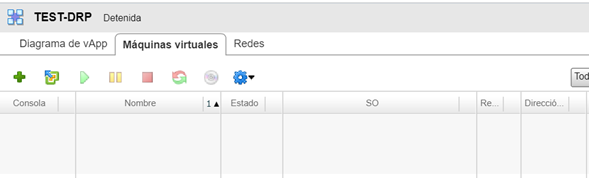
Podemos visualizar, en el Datacenter de Contingencia, como el servidor ha sido borrado y su vApp ha quedado en estado Detenida.

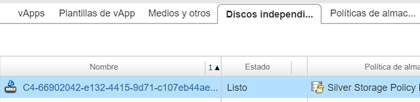
Podemos visualizar en el registro como se eliminó el servidor y como se ha creado el disco independiente asociado al servicio de réplica.
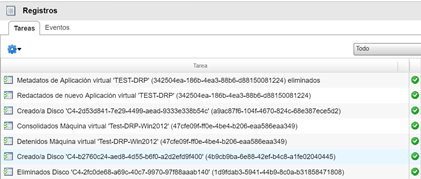
Para propósitos de esta prueba, el proceso de re-protección duró casi 10 minutos.

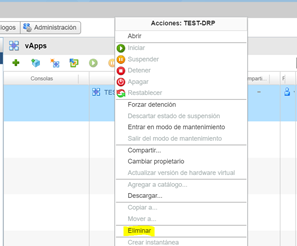
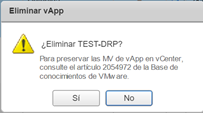
Una vez finalizado el proceso, podemos borrar manualmente las vApps que quedaron huérfanas en ambos Datacenters y renombrar nuestra vApp en el Datacenter Principal, para mantener el orden de estas.
Y con esto hemos concluido nuestro artículo de hoy. Para finalizar, en el último artículo de esta serie veremos las diferencias entre efectuar un failover y una migración del servidor. ¡Será hasta la próxima!