En esta serie de artículos hemos revisado a nivel de detalle el proceso de Disaster Recovery de servidores virtuales, utilizando la herramienta vCloud Availability de VMware. Este proceso parte con la protección, el failover, la protección reversa (para establecer la réplica en sentido inverso), el failback o failover reverso y posteriormente la re-protección.
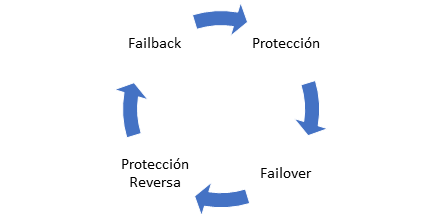
Sin embargo, vCloud Availability tiene una opción adicional para hacer el proceso de failover, llamado migrate. ¿Qué diferencias tiene con el failover y cuál es el rendimiento de este proceso? Vamos a revisar esta opción en el último artículo de esta serie.
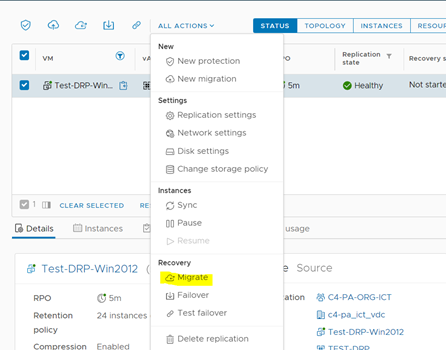
El primer detalle relevante al utilizar esta opción es que el asistente nos indica inmediatamente que el servidor del Datacenter Principal, una vez terminado el proceso, se apagará. En este sentido, el proceso de migración, a diferencia del proceso de failover, está pensado para escenarios en donde ambos datacenters se encuentran operativos. En ese sentido, el servidor migrado se debe apagar en el Datacenter Principal para no causar conflictos a nivel de red.
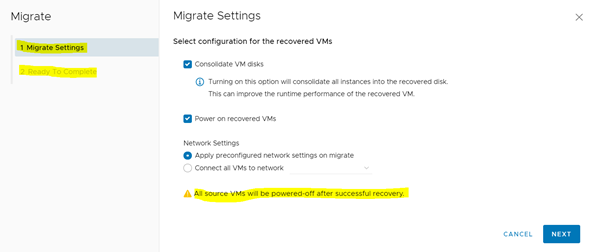
Otro aspecto relevante de este proceso es que no permite seleccionar instancias anteriores. Se sincroniza siempre con la última réplica.
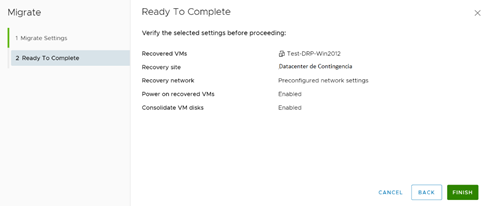

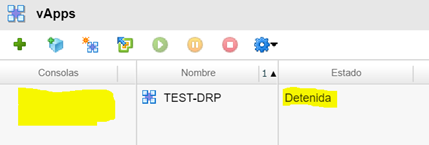
Podemos visualizar que en el Datacenter Principal, apenas inicia el proceso, el servidor de pruebas cambia a estado de ejecución parcial.
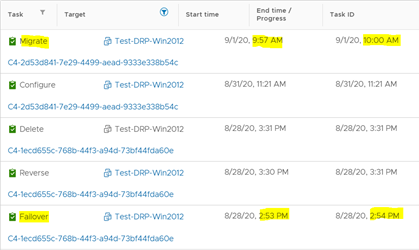
El proceso de migración duró 3 minutos, comparado con el proceso de failover para el mismo servidor que duró poco más de un minuto.
Una vez finalizado el proceso de migración, el servidor en nuestro Datacenter Principal se ha detenido, mientras aparece en ejecución en nuestro Datacenter de Contingencia.

El resto del proceso es similar; toca ahora hacer la reversa.
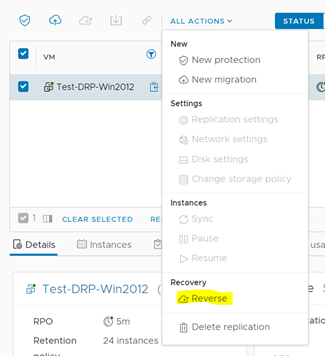
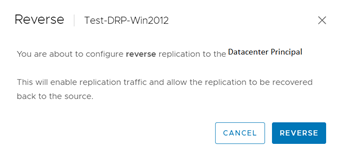


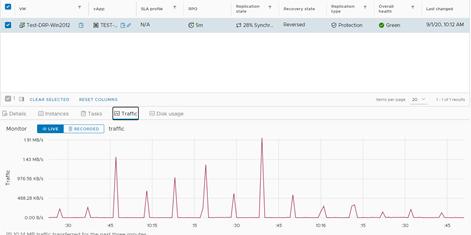
El proceso de sincronización reversa duró 6 minutos, bastante más que los 2 minutos que duró la protección reversa cuando aplicamos la opción de failover.

Luego realizaremos el failback utilizando la misma opción de migración, para comparar los tiempos de ejecución de las actividades.
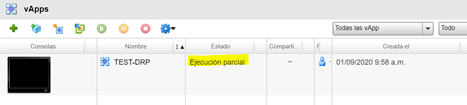
Al igual que como sucedió en el proceso de failover, el failback utilizando la opción de migración tomó más tiempo que el proceso de failback que realizamos anteriormente.
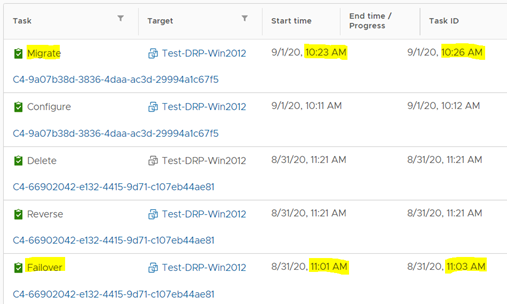
Para finalizar las pruebas, haremos la re-protección y cerraremos así el proceso. Lamentablemente para propósitos de esta prueba, el proceso de re-protección se realizó en paralelo con la sincronización de un servidor altamente transaccional, por lo cual los tiempos de sincronización no son comparables.
En resumen, utilizar la opción de migración en vez de utilizar la opción de failover en vCloud Availability tiene como principal diferencia el hecho de que no deja utilizar instancias anteriores para el proceso, además del hecho de que apaga forzosamente el servidor en el Datacenter de Origen una vez finalizado el proceso. Si bien las pruebas realizadas no son 100% concluyentes, se puede indicar que el proceso de migración es ligeramente más lento que el proceso de failover, ya que añade tareas adicionales que el proceso anteriormente mencionado. Es un proceso pensado para utilizar en escenarios donde ambos Datacenters se encuentren operativos.
Con esto terminamos esta serie de artículos sobre esta herramienta de DRP como servicio, nativa de VMware y que ha mejorado una enormidad desde su primera versión. ¡Nos vemos pronto en otro artículo de seguridad y continuidad de negocio!
